1. Introduction
1.1 Containerized Microservices
Traditionally, software systems were designed using a monolithic architecture. In this architecture, each piece of the system is a part of one large code base which is deployed as a single program.1
Modern software systems often use a microservice architecture, in which individual parts of a system have been split up into independent applications and are referred to as services. Unlike a monolithic architecture, the individual services in a microservice architecture are loosely coupled and can be independently tested, deployed, and scaled. Microservices can use different technology stacks and can be maintained by smaller, autonomous teams.2
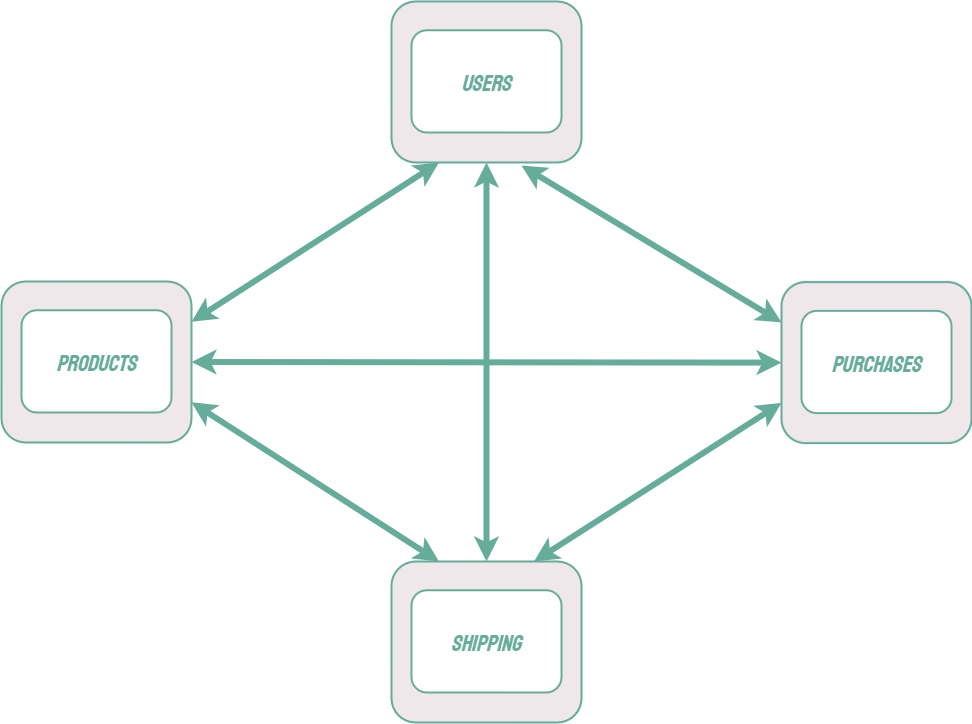
A microservice architecture comes with its own unique set of challenges. For example, each microservice should be able to scale independently. Each microservice may consist of multiple instances of the same application which can be added or removed in response to fluctuating traffic demands. This scaling introduces other concerns, such as load balancing and the provisioning of new resources.
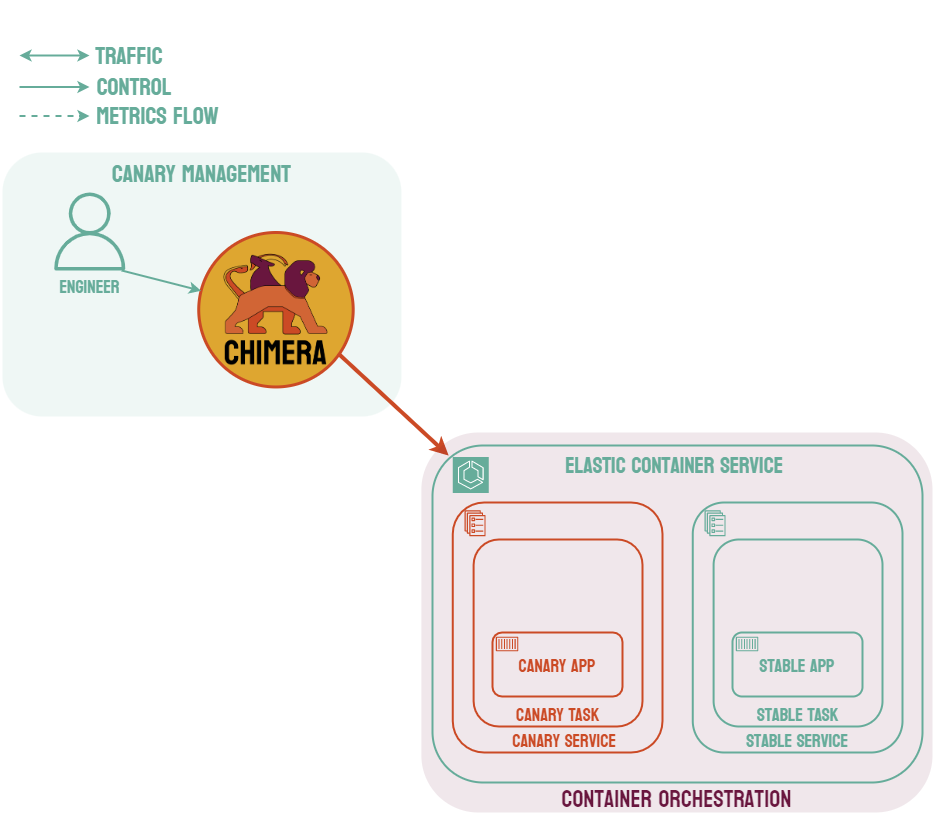
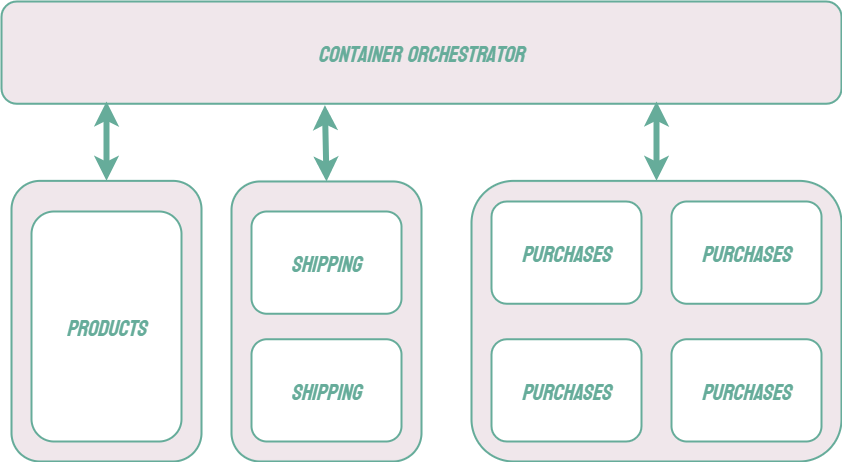
A common solution to these challenges is known as container orchestration. Applications can be packaged as container images using a tool like Docker, and a container orchestration tool can handle, among other features, provisioning resources to run the application, scaling as needed, and performing load balancing to ensure that no single instance of the application is overwhelmed.3 There are many container orchestration tools such as Kubernetes, Docker Swarm, and AWS Elastic Container Service.
In a monolithic architecture, individual components of a system communicate via method or function calls. Microservices, on the other hand, must communicate via networking protocols such as HTTP or AMQP. As a microservice architecture grows, it can include many services and the communications between them can become very complex. Each service must have the logic that controls these communications built into it, including how it can interact with the other services and what should happen if another service fails to respond. As a system grows and changes, each service must independently keep up with how this communication logic changes.
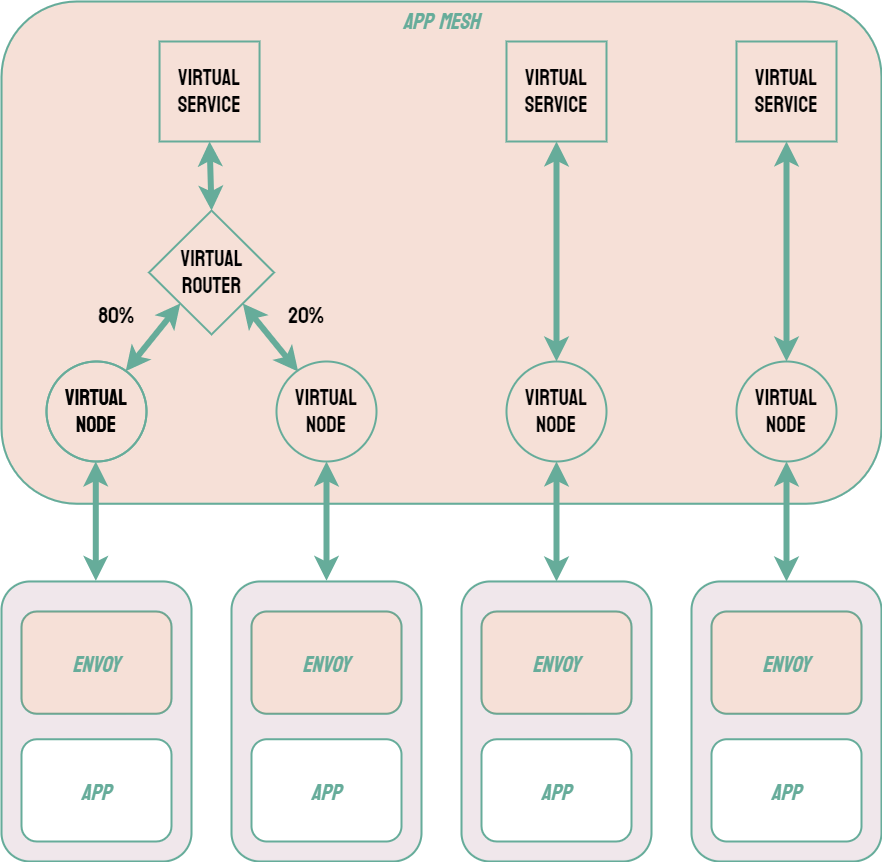
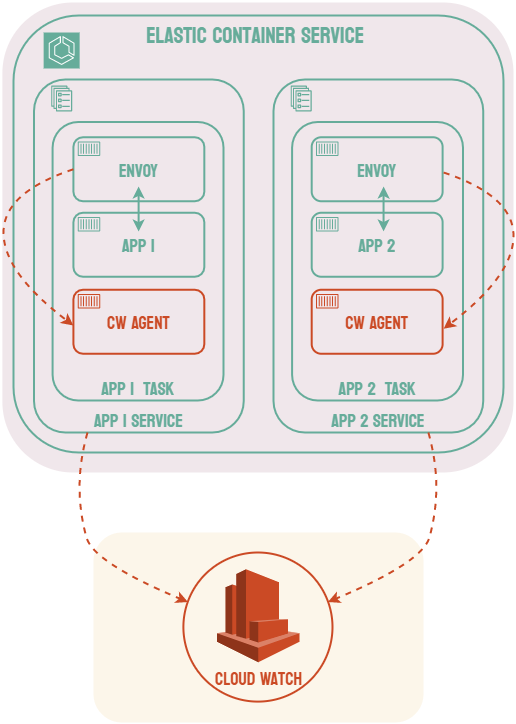
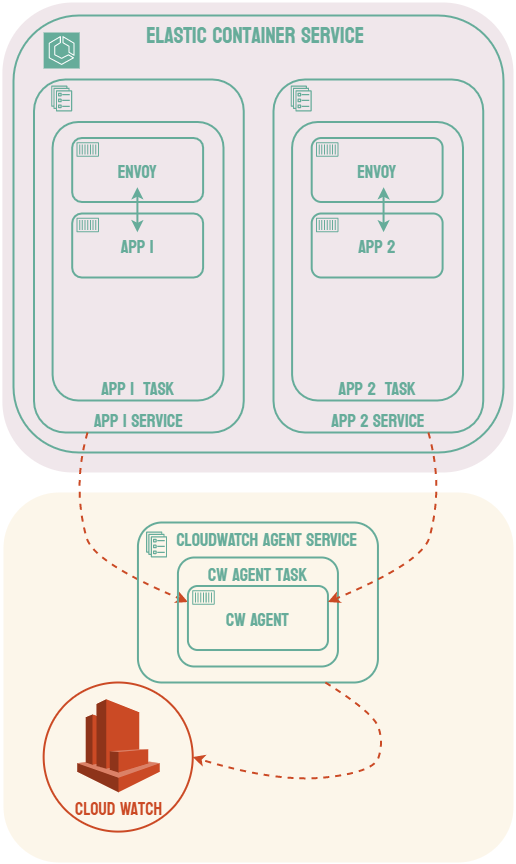
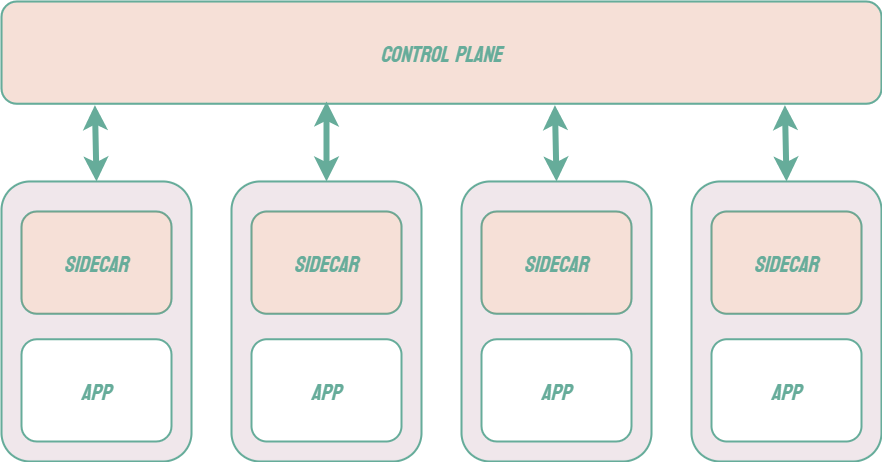
One possible solution to this problem is to include an additional layer to the infrastructure known as a service mesh. When using a service mesh, each microservice is associated with a sidecar proxy which intercepts requests to and from the service. These proxies are referred to as the data plane of the service mesh and handle the complexities of inter-service communication. The developer can control and configure these proxies via the control plane of the service mesh.4 Common examples of service mesh products include Istio, Linkerd, and AWS App Mesh.
1.2 Deploying Microservices
Designing and writing code is only a part of the process of creating a new version of an application and providing new or improved features for your users. A very important part of the process is delivering the new version and making it available. This is why a robust Continuous Integration and Continuous Delivery (CI/CD) pipeline is essential. When a CI/CD pipeline is performing correctly, teams can iterate incrementally and rapidly. Modern software teams commonly deploy new versions of their code several times a day. In order to achieve this, the steps of the deployment process must be automated, reliable, and have minimal impact on the application’s users.
A typical CI/CD pipeline will include automated steps for building and testing new code as it is pushed into a code repository. This process ensures that at any given point, all code in a repository has been tested and meets whatever standards have been established. Once this has been done, the goal is to make the new version available to users as soon as possible. This kind of fast iteration allows teams to “fail fast”, which in turn allows the team to identify any problems as soon as possible. This goal needs to be balanced with the goal of providing the best possible customer experience and careful thought needs to be put into how the deployment process can achieve both goals.5
Traditional Deployments
The traditional and most simple deployment strategy is known as an “All-at-Once” deployment. Using this strategy, the application is simply taken offline at a designated time. While it is offline, it is replaced with the new version of the application. Once the process is completed, the new version is made available to users. While it is relatively simple, there are several problems with this strategy. While the software is being updated, it is inaccessible to users. Availability is a major concern for modern software systems as it has a very direct and clear impact on both revenue and the user experience. For that reason, this process can not be performed frequently and the team will not be able to rapidly iterate and release new features.
Another significant problem with this approach is that flaws in the new software could potentially impact every user. Further, if a flaw is identified, rolling back to a previous version requires another deployment and more, potentially unplanned, downtime.
Rolling Deployments
When using a microservice architecture, it is common to have multiple instances of an application running concurrently to scale as traffic increases or decreases. When this is the case, it is possible to use a rolling deployment strategy. Using this strategy, individual instances of the application can be taken down and replaced with the new version one by one. This keeps the application available to users during the deployment, and it also helps to reduce the number of users that may be affected by bugs in the new code.
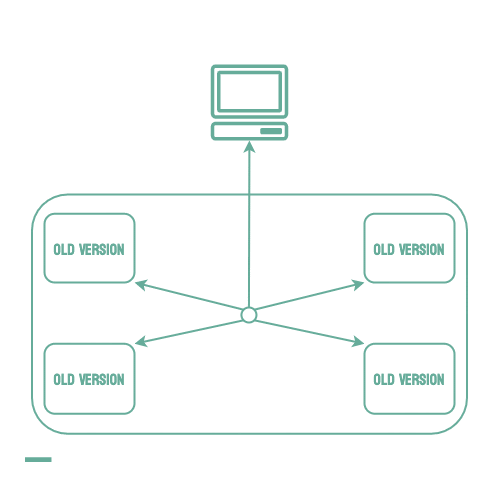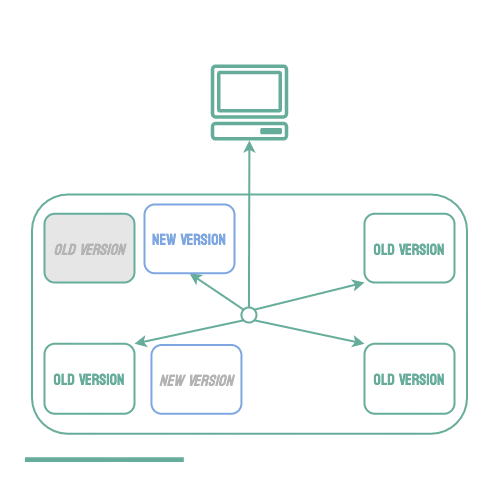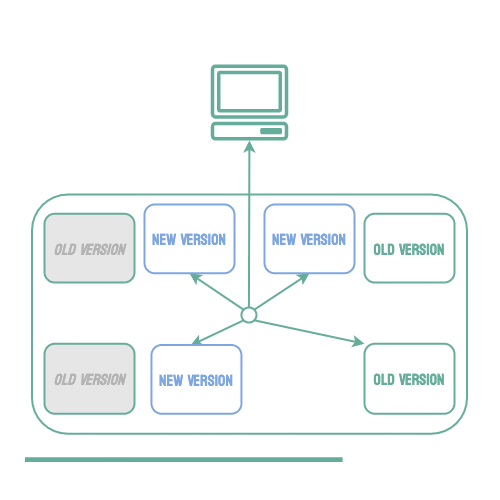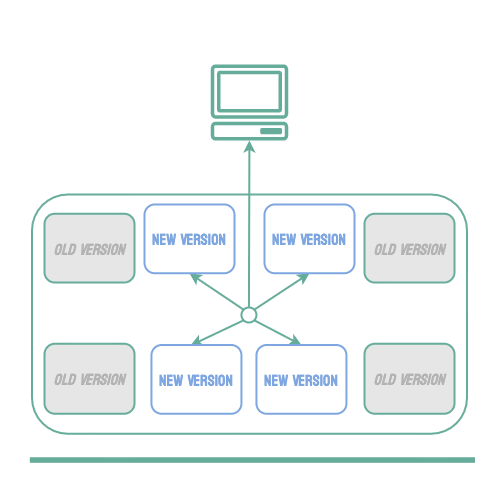
Unfortunately, if an issue is found and a rollback must occur, all of the new instances must be stopped and any of the old instances that have already been taken down must be restarted. This means your service will be operating at limited capacity until all of the old instances are back up, which may create availability issues, especially if the error is identified late in the deployment process. This strategy is also not possible unless the service consists of multiple instances, which is not always the case.
Blue-Green Deployments
An alternative to all-at-once and rolling deployments is known as a blue-green deployment. Using this strategy, the new version of the software (the green environment) is deployed while the stable version (the blue environment) is still running. Once the new version is running, 100% of traffic is routed to it. The benefit of this strategy is that it removes downtime. Users can still access the stable deployment while the new version is starting. Then, if any issues arise 100% of traffic can be shifted back to the stable version. Once the team is confident the new service is working as expected, the new version becomes the stable environment and the old version can be brought down.
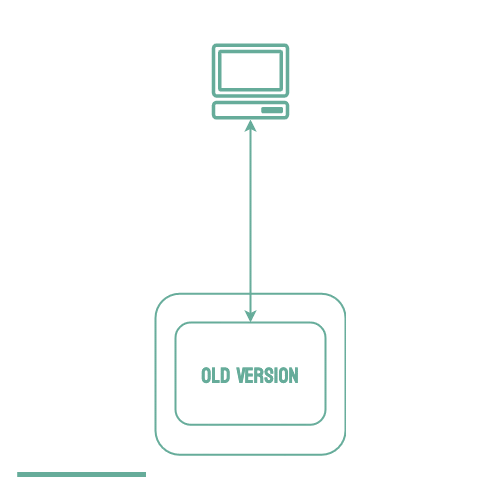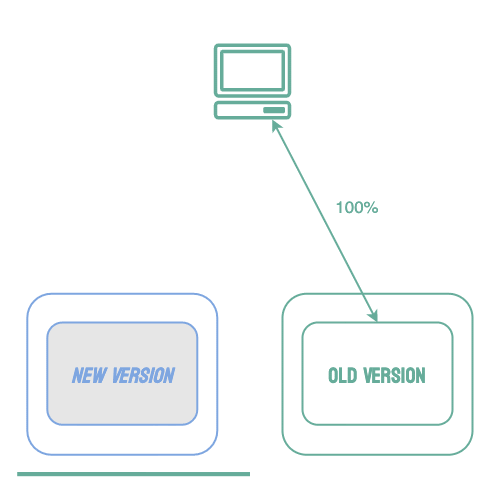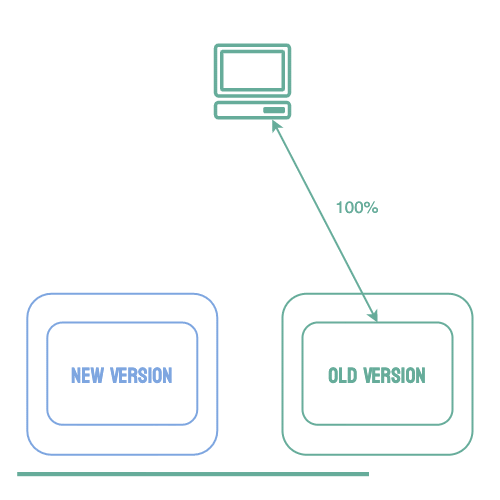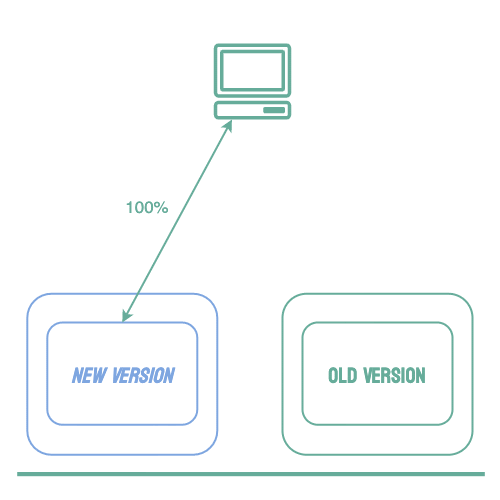
Blue-green deployments solve the problem of reducing downtime, but errors in the new software can still affect every user of the application.
Canary Deployments
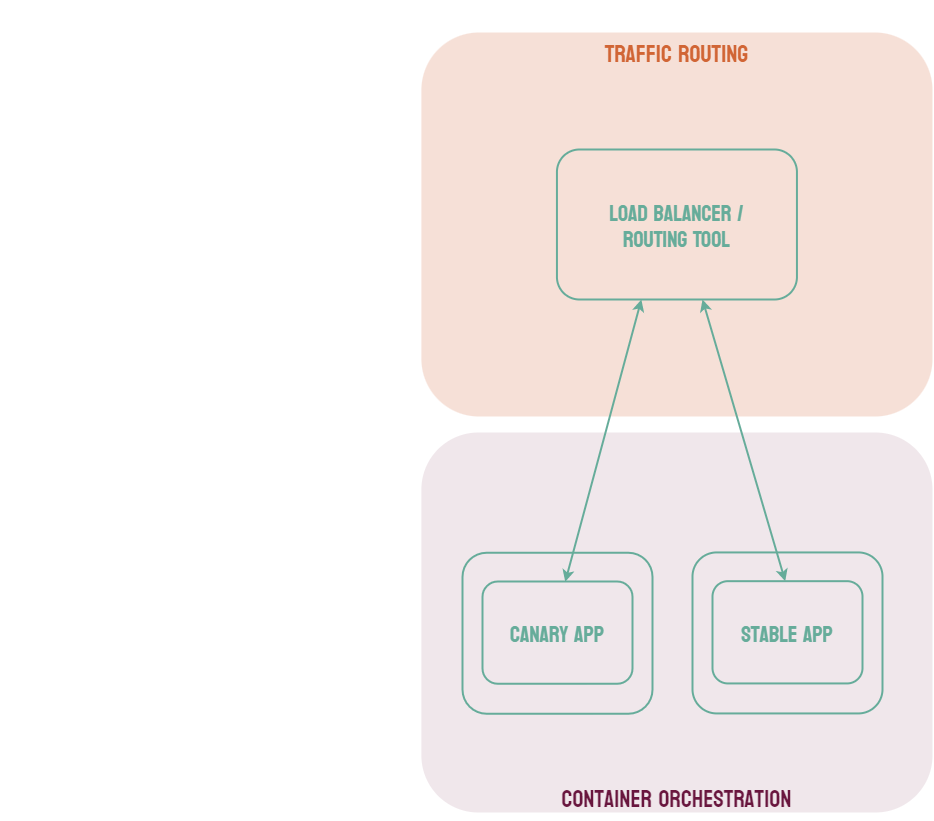
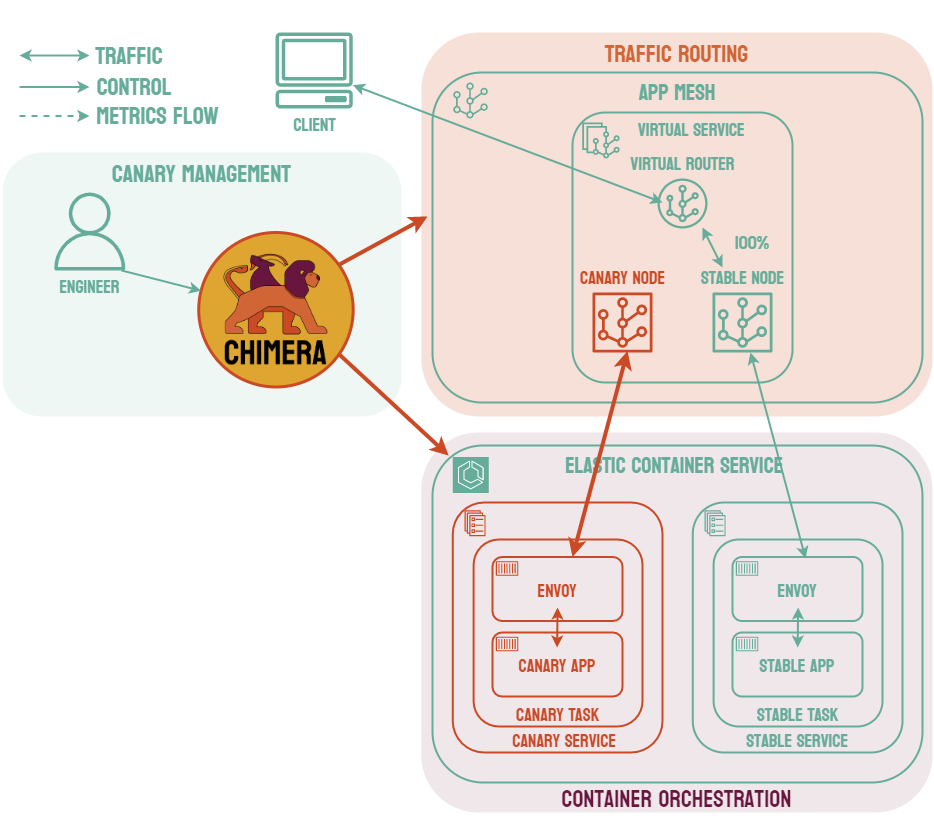
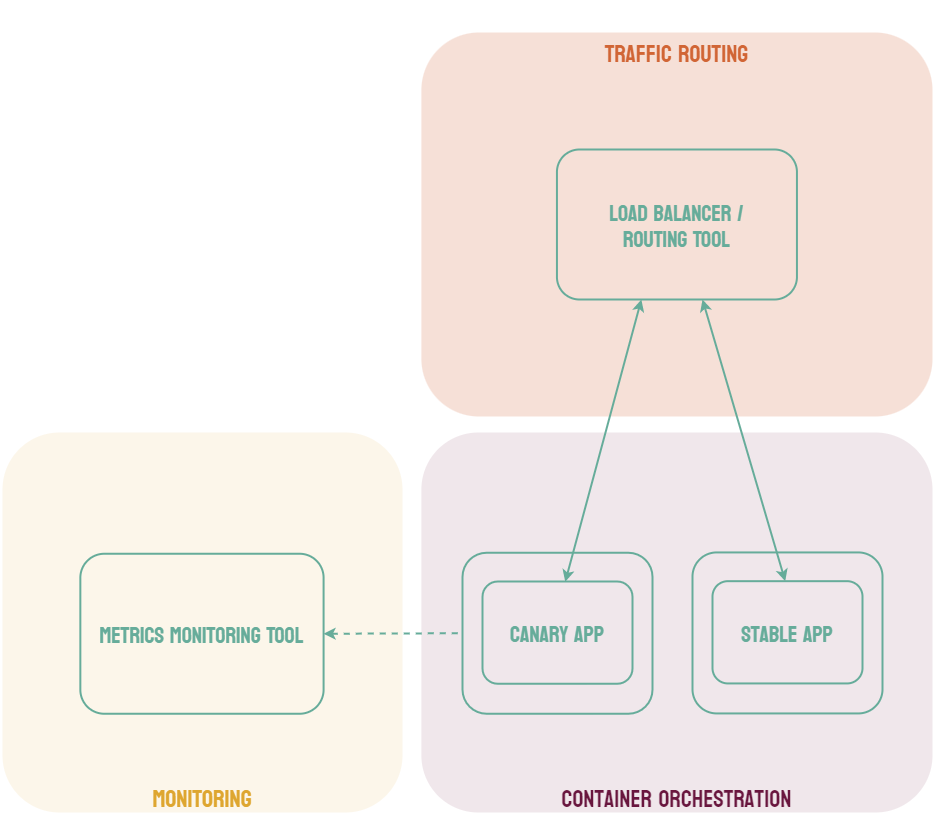
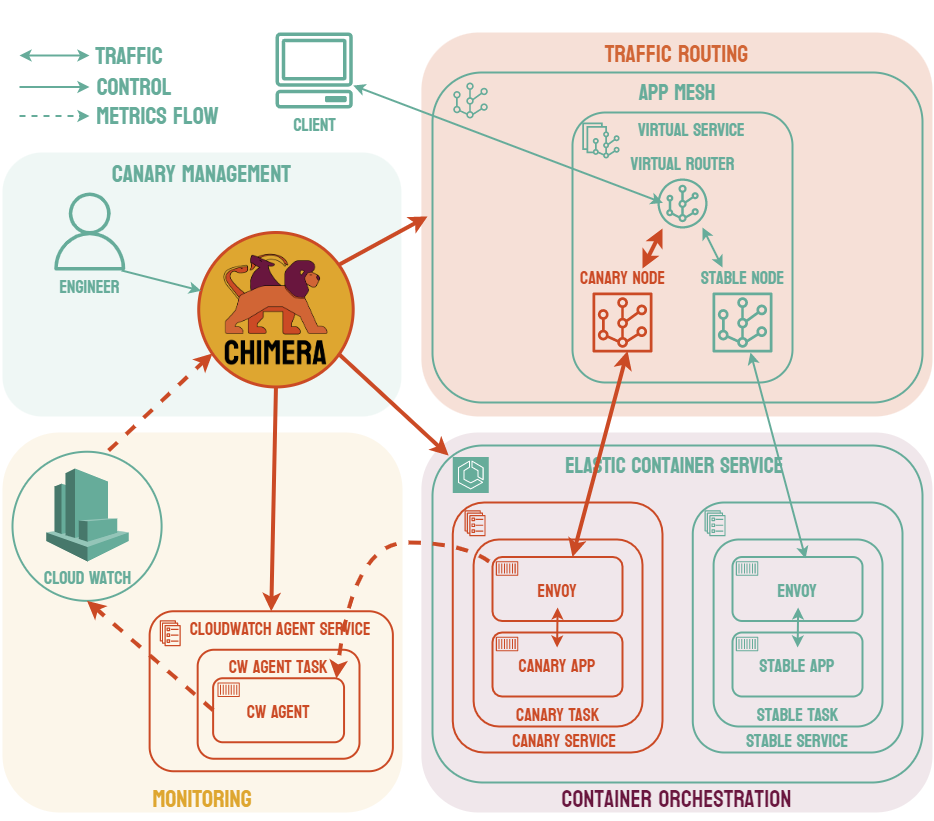
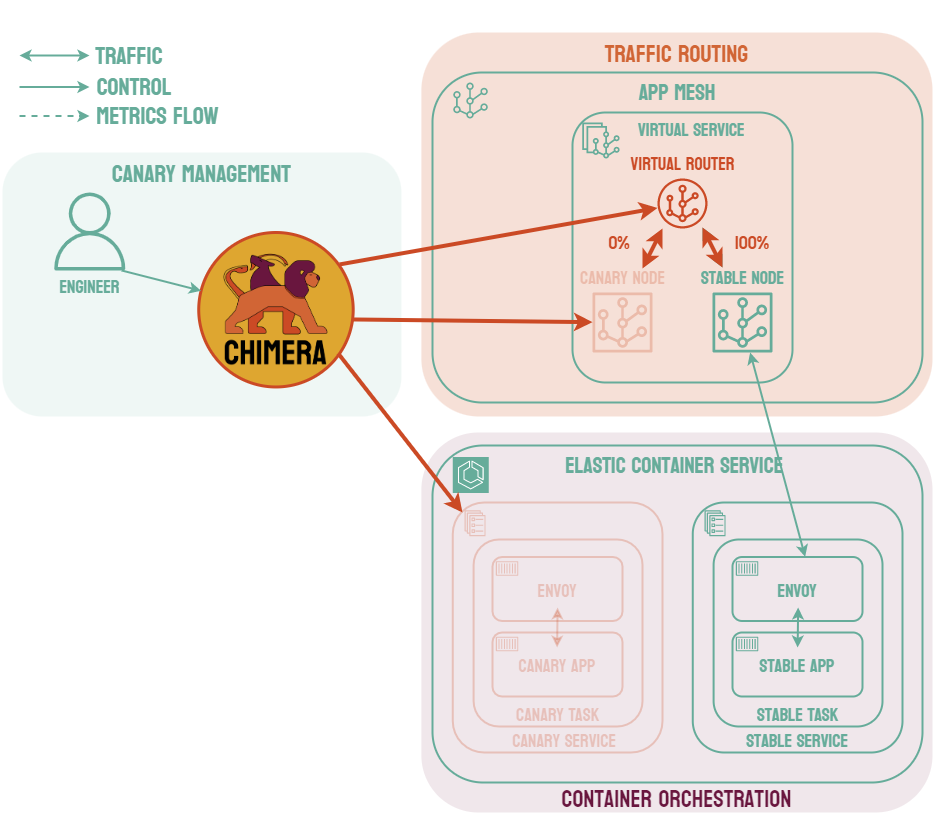
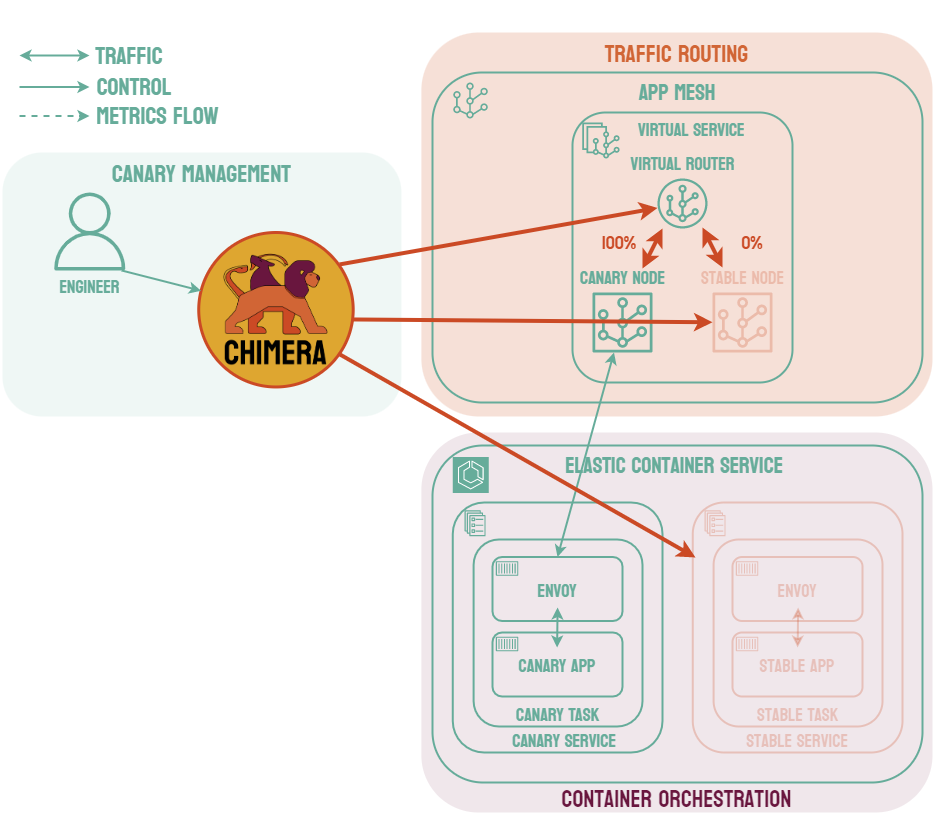
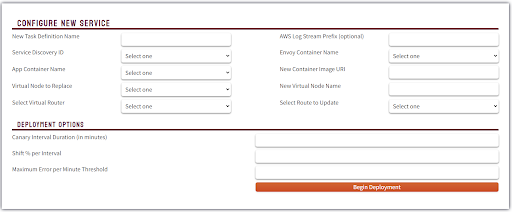
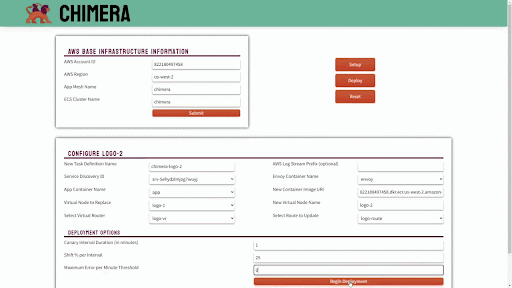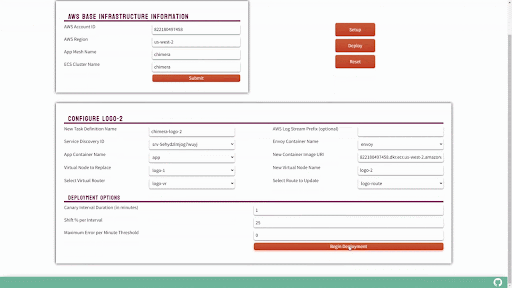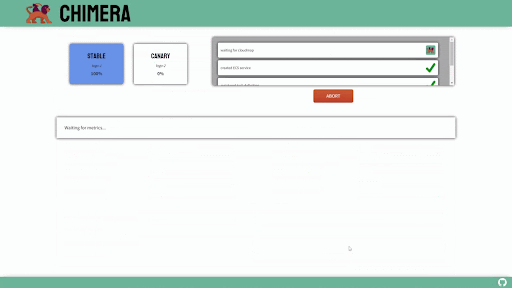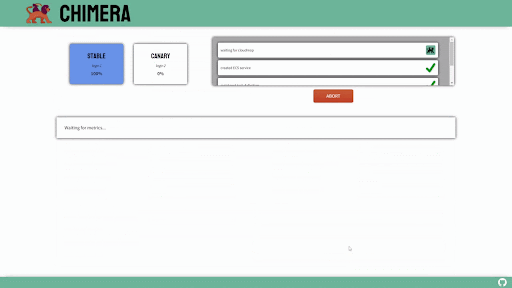
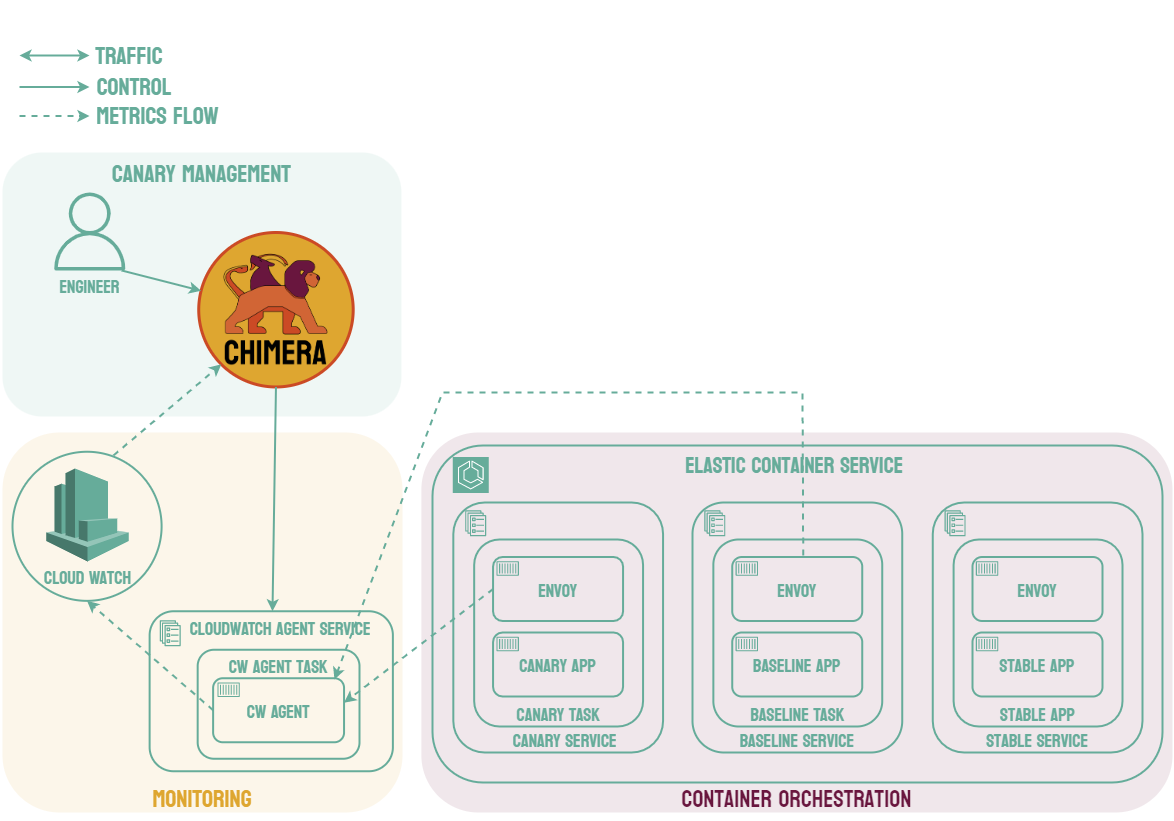
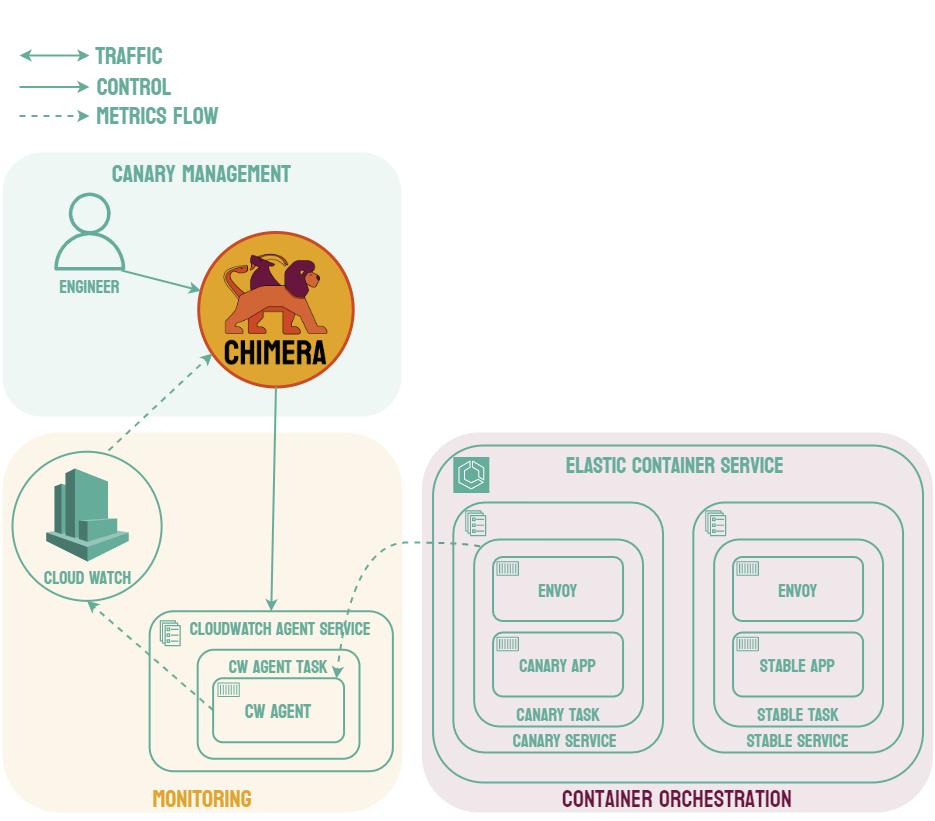
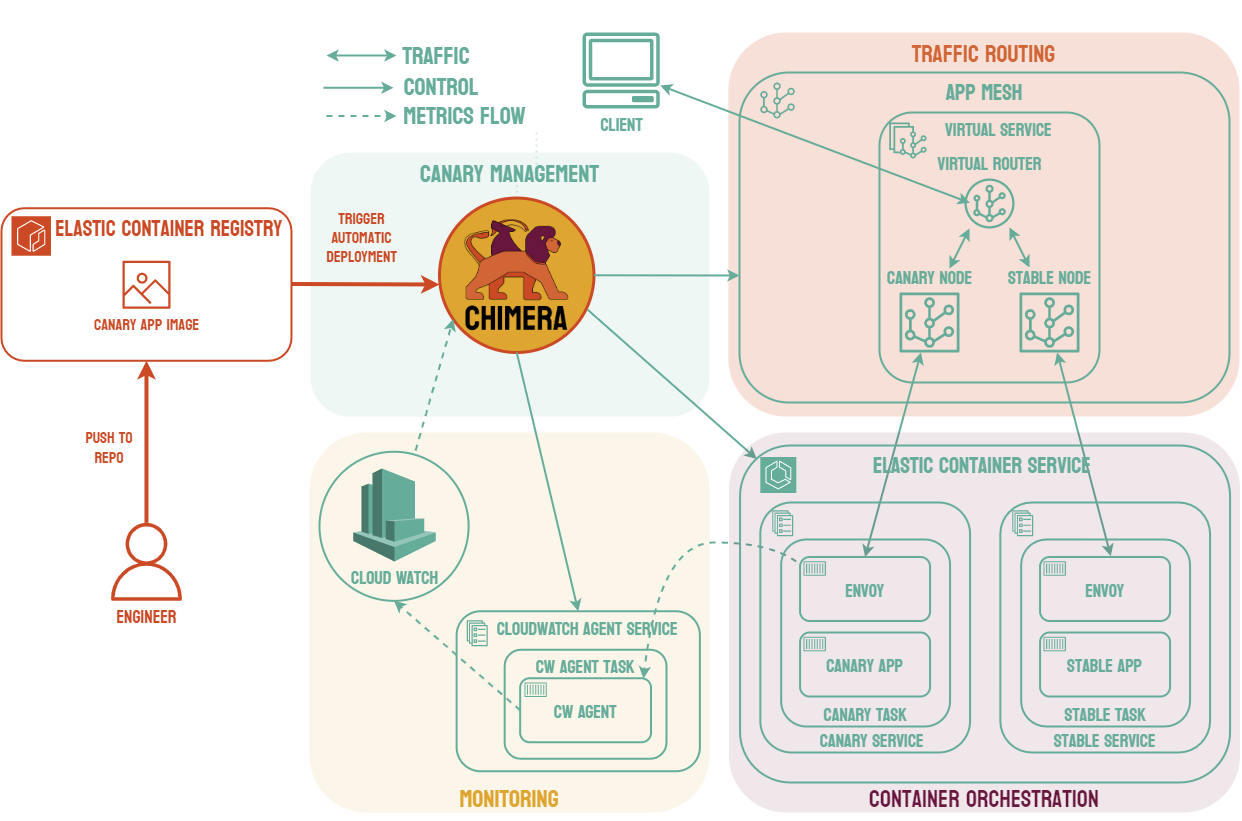
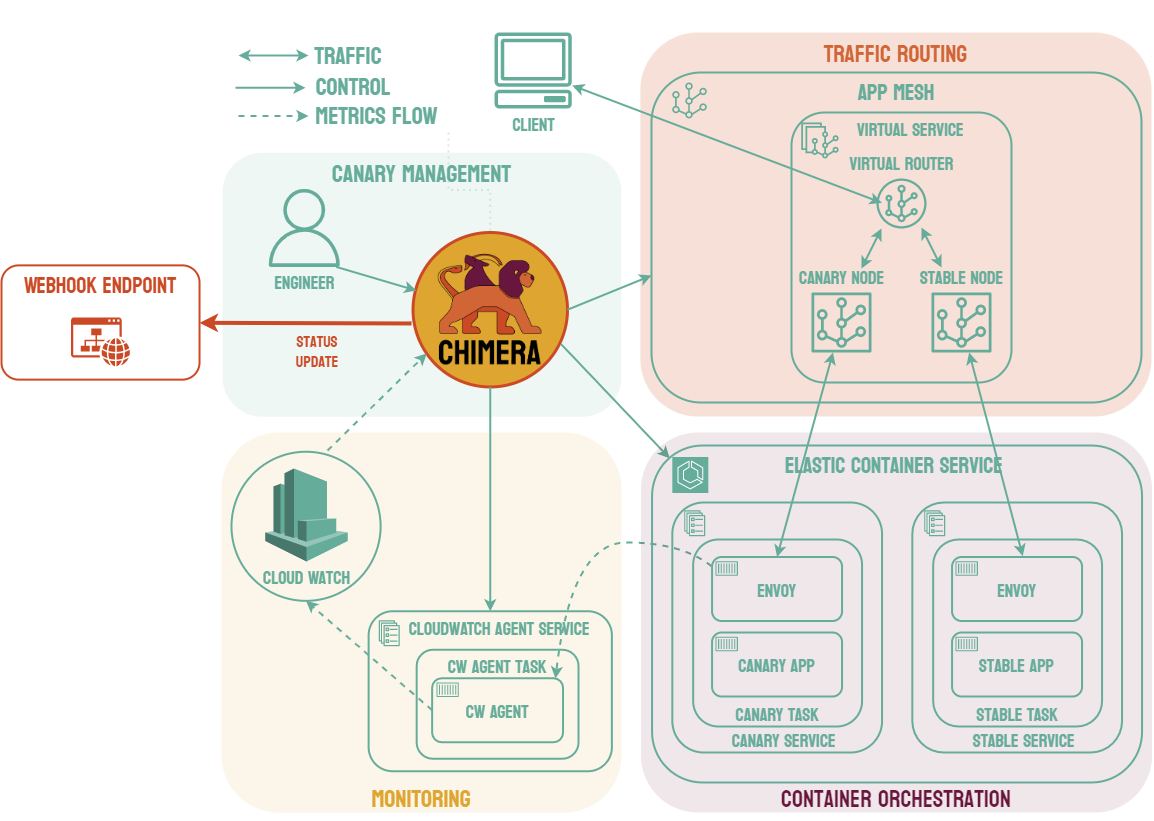
Canary deployments are similar to blue-green deployments in that a new version, which we refer to as the canary, is deployed while the stable version is still running. The difference is that traffic is not shifted all at once, but is instead shifted incrementally over a predetermined time frame, referred to as an interval. In order to achieve this, some tool capable of performing load balancing must be placed in front of the stable version and the canary.
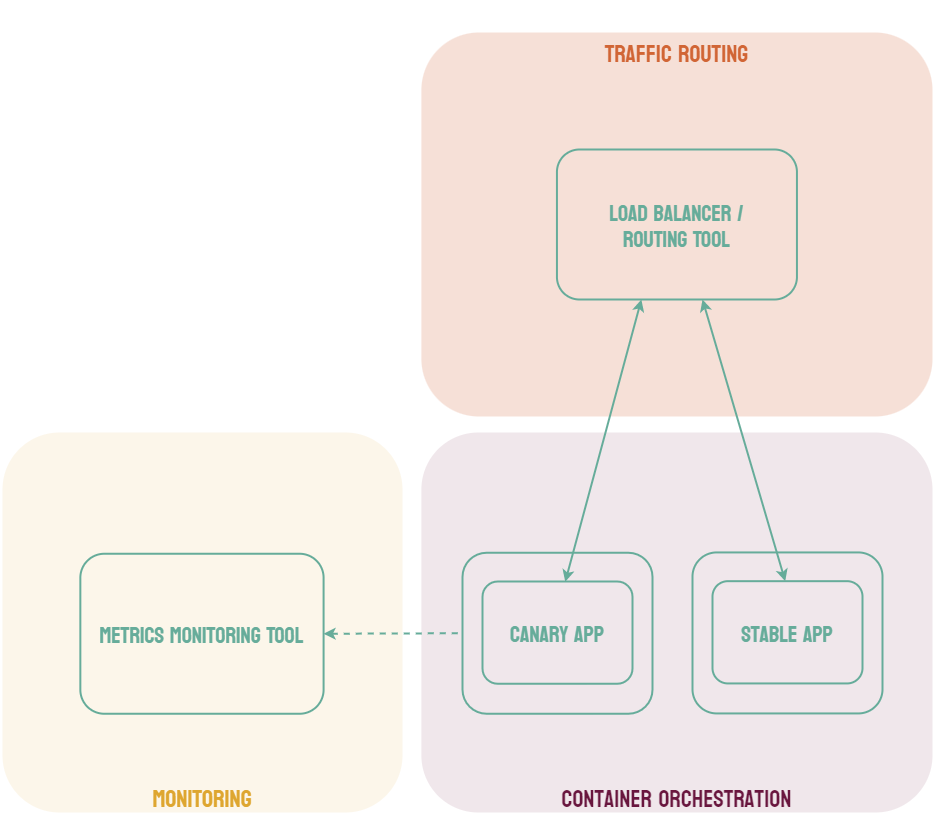
As traffic is slowly shifted to the canary, performance metrics can be analyzed that will inform the decision of whether more traffic should be shifted or if a rollback to the stable version should occur. Once 100% of the traffic is shifted to the canary, the stable version can be removed and replaced with the new version of the code. On the other hand, if it is determined that the canary is not stable enough to be used in production, traffic can be shifted back to the stable version and the canary will be removed.6
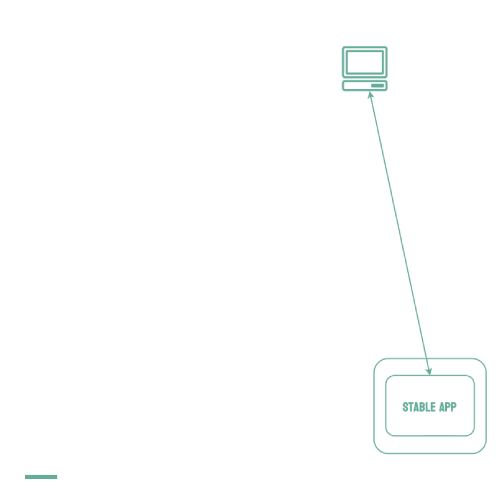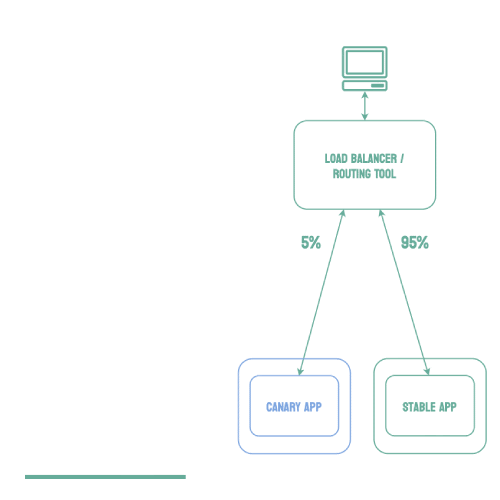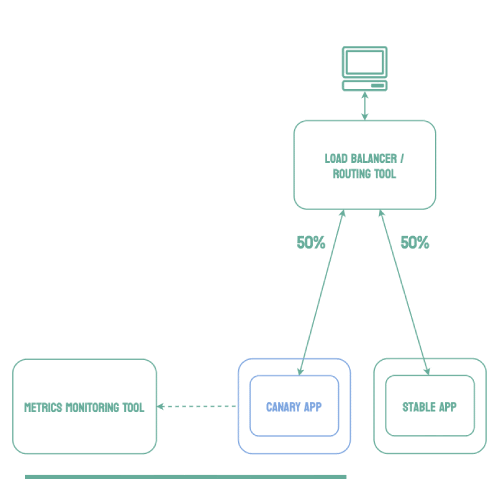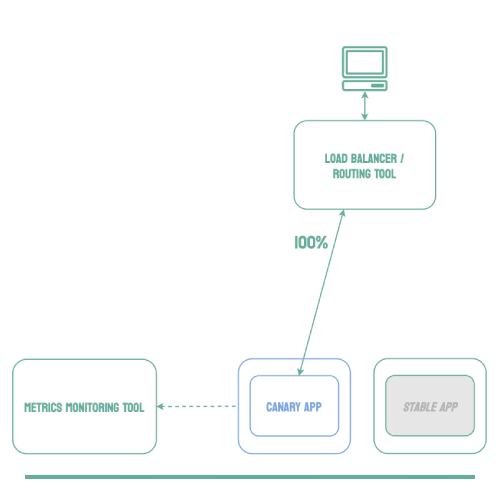
Using canary deployments, there is no downtime and the application remains available to users throughout the process. It also serves to minimize the amount of users that may be negatively impacted by errors in the new version of the code.
These features come at the cost of increased complexity, as canary deployments require many more moving parts than other deployment strategies. Most of the added complexity requires real-time manual intervention, such as determining whether more traffic can be shifted. Canary deployments also require an extended length of time compared to other strategies, sometimes spreading the traffic shifting over several hours.7